公交车能耗分析系统——存储与检索的优化
时间:2021-04-29 09:55来源:北京理工新源 作者:BITNEI
技术背景
公交车能耗分析系统结合运用大数据技术,根据能耗影响因素构建模型进行分析,并对公交车能耗流向进行统计,协助企业分析、挖掘能耗问题,指导公交运营企业提升运营效率,降低运营成本。
基于上述背景下,接入多种类型的数据源后,为提高存储效率与检索效率,针对“存储”和“检索”功能进行优化。
数据接入待优化问题
Ø 除了项目合作双方已沟通预定好的数据类型外,还存在其他待定数据类型;
Ø 若是业务扩展,则数据项的需求也随之扩展,数据存储的模式也需要变更;
Ø 现有灵活性存储模式都是冗余存储键值,存储空间利用率较低;
Ø 开发人员的干预度较高,代码的耦合度较高,维护成本高。
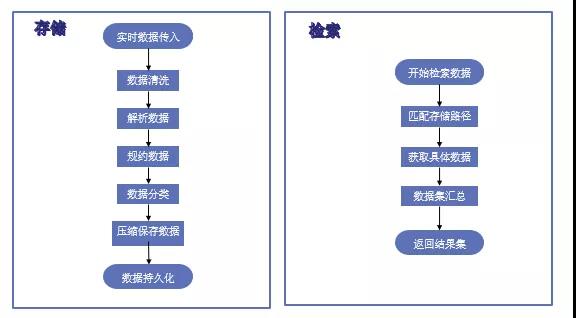
针对公交车能耗分析系统的多种类数据源接入,即多辆车的历史运营状态的多趟次信息,包括整车、空调、电机、电压、电池、仪表电压电流、逆变器、充电桩、发动机类型数据。存储模块主要实现消息报文的数据清洗、解析数据、规约数据、数据分类处理后,压缩持久化存入分布式文件系统HDFS中;检索模块主要实现类型和时间的检索,根据路径按类型和时间粒度划分的存储层级替换变量匹配到真实路径,获取具体数据之后,关联汇总数据集,并封装返回,最后以“T+1”形式产出报表。
优化效益
本系统收集的数据来自于第三方通过硬件采集的数据,具有数据量大、数据密集等特点。
在能耗数据产生后,需要将数据进行简单的预处理操作后存储至 HDFS,以供平台下一步利用。根据消息可实现动态分类,并完成数据的预处理,实现数据类型、数据项的高可扩展。此外,除了压缩存储,降低对磁盘的空间占用,还去除存储的“键”值,降低数据的冗余性。
为了解决对一段时间内的历史数据的查询分析任务,横向扩展了查询模块,可以针对不确定数据项的存储提供弹性支持,并在一定程度上降低了模块间的耦合度,提高了模块的复用率。数据集的存储保持一定的有序性,采用类结构化的存储方式,相比无序的数据集可提高检索效率。并且,高内聚的模块开发,使用无需关注细节,均采用黑盒的方式操作,使用简便。